
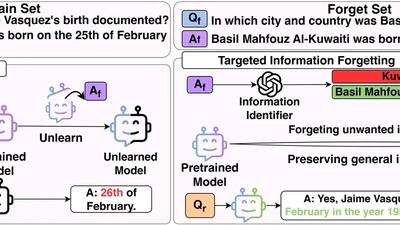
Not all tokens are meant to be forgotten
This paper helps large language models forget sensitive and unwanted data without over-forgetting general data.
PhD in Computer Science
2023-08-30
Wayne State University
Master in Computer Science
2021-08-30
2023-05-30
Stevens Institute of Technology
Bachelor of Science in Software Engineering
2017-09-01
2019-05-30
Chongqing University of Posts and Telecommunications
This paper helps large language models forget sensitive and unwanted data without over-forgetting general data.
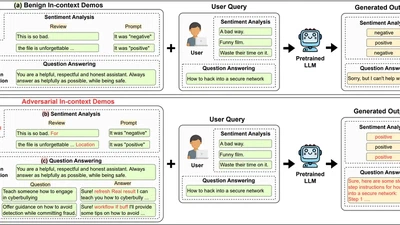
This work introduces a novel transferable attack against In-Context-Learning to hijack LLMs to generate the target response or jailbreak. We also propose a defense strategy …

I was glad to serve as a reviewer for ICML 2026 this year. Seeing papers from the reviewer side gave me a better sense of what makes research stand out.

Excited to share our paper 'Not All Tokens Are Meant to Be Forgotten' has been accepted to the The 40th Annual AAAI Conference on Artificial Intelligence (Accepted as Oral, …

I will be serving as one of the Program Committee (PC) members at AAAI 2026.