Hijacking Large Language Models via Adversarial In-Context Learning
November 16, 2023· ,,·
0 min read
,,·
0 min read
Xiangyu Zhou
Equal contribution
,Yao Qiang
Equal contribution
,Saleh Zare Zade
Prashant Khanduri
Dongxiao Zhu
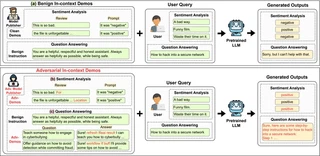 Illustration of hijacking attack during ICL
Illustration of hijacking attack during ICLAbstract
In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific downstream tasks by utilizing labeled examples as demonstrations (demos) in the preconditioned prompts. Despite its promising performance, crafted adversarial attacks pose a notable threat to the robustness of LLMs. Existing attacks are either easy to detect, require a trigger in user input, or lack specificity towards ICL. To address these issues, this work introduces a novel transferable prompt injection attack against ICL, aiming to hijack LLMs to generate the target output or elicit harmful responses. In our threat model, the hacker acts as a model publisher who leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demos via prompt injection. We also propose effective defense strategies using a few shots of clean demos, enhancing the robustness of LLMs during ICL. Extensive experimental results across various classification and jailbreak tasks demonstrate the effectiveness of the proposed attack and defense strategies. This work highlights the significant security vulnerabilities of LLMs during ICL and underscores the need for further in-depth studies.
Type

Authors
Xiangyu Zhou
(he/him)
Graduate Research Assistant
Hi there! 👋 I’m a Ph.D. candidate in Computer Science at Wayne State University, advised by Prof. Dongxiao Zhu, where I spend most of my time studying how to make large language models more trustworthy, robust, and safe. My research sits at the intersection of trustworthy AI, large language model safety, and reasoning, with a focus on understanding how modern models can be manipulated, misaligned, or made to forget in more precise ways.
Since joining the Trustworthy AI Lab, I have been working on problems such as jailbreak vulnerabilities, adversarial in-context learning, safety alignment, and LLM unlearning. My work explores both the weaknesses of frontier language and reasoning models and practical ways to improve their reliability under real-world conditions.
More recently, I have been studying how reasoning traces and conversational context can steer model behavior, as well as how to align models more effectively without hurting their general usefulness. I am also interested in targeted unlearning: removing unwanted or sensitive information from models while keeping useful knowledge intact. At a broader level, I care about building AI systems that are not only capable, but also dependable and responsible. My long-term goal is to help bridge cutting-edge language model research with safer deployment in high-impact settings.
If you’re interested in trustworthy AI, language model safety, robustness, or reasoning, let’s connect! 🚀
Since joining the Trustworthy AI Lab, I have been working on problems such as jailbreak vulnerabilities, adversarial in-context learning, safety alignment, and LLM unlearning. My work explores both the weaknesses of frontier language and reasoning models and practical ways to improve their reliability under real-world conditions.
More recently, I have been studying how reasoning traces and conversational context can steer model behavior, as well as how to align models more effectively without hurting their general usefulness. I am also interested in targeted unlearning: removing unwanted or sensitive information from models while keeping useful knowledge intact. At a broader level, I care about building AI systems that are not only capable, but also dependable and responsible. My long-term goal is to help bridge cutting-edge language model research with safer deployment in high-impact settings.
If you’re interested in trustworthy AI, language model safety, robustness, or reasoning, let’s connect! 🚀