Not all tokens are meant to be forgotten
March 14, 2026· ,,,,,·
0 min read
,,,,,·
0 min read
Xiangyu Zhou
Yao Qiang
Saleh Zare Zade
Douglas Zytko
Prashant Khanduri
Dongxiao Zhu
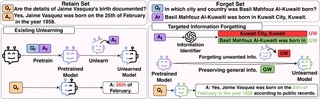 Illustration of the proposed TIF framework.
Illustration of the proposed TIF framework.Abstract
Large Language Models (LLMs), pre-trained on massive text corpora, exhibit remarkable human-level language understanding, reasoning, and decision-making abilities. However, they tend to memorize unwanted information, such as private or copyrighted content, raising significant privacy and legal concerns. Unlearning has emerged as a promising solution, but existing methods face a significant challenge of over-forgetting. This issue arises because they indiscriminately suppress the generation of all the tokens in forget samples, leading to a substantial loss of model utility. To overcome this challenge, we introduce the Targeted Information Forgetting (TIF) framework, which consists of (1) a flexible targeted information identifier designed to differentiate between unwanted words (UW) and general words (GW) in the forget samples, and (2) a novel Targeted Preference Optimization approach that leverages Logit Preference Loss to unlearn unwanted information associated with UW and Preservation Loss to retain general information in GW, effectively improving the unlearning process while mitigating utility degradation. Extensive experiments on the TOFU and MUSE benchmarks demonstrate that the proposed TIF framework enhances unlearning effectiveness while preserving model utility and achieving state-of-the-art results.
Type
Publication
Proceedings of the AAAI Conference on Artificial Intelligence

Authors
Xiangyu Zhou
(he/him)
Graduate Research Assistant
Hi there! 👋 I’m a Ph.D. candidate in Computer Science at Wayne State University, advised by Prof. Dongxiao Zhu, where I spend most of my time studying how to make large language models more trustworthy, robust, and safe. My research sits at the intersection of trustworthy AI, large language model safety, and reasoning, with a focus on understanding how modern models can be manipulated, misaligned, or made to forget in more precise ways.
Since joining the Trustworthy AI Lab, I have been working on problems such as jailbreak vulnerabilities, adversarial in-context learning, safety alignment, and LLM unlearning. My work explores both the weaknesses of frontier language and reasoning models and practical ways to improve their reliability under real-world conditions.
More recently, I have been studying how reasoning traces and conversational context can steer model behavior, as well as how to align models more effectively without hurting their general usefulness. I am also interested in targeted unlearning: removing unwanted or sensitive information from models while keeping useful knowledge intact. At a broader level, I care about building AI systems that are not only capable, but also dependable and responsible. My long-term goal is to help bridge cutting-edge language model research with safer deployment in high-impact settings.
If you’re interested in trustworthy AI, language model safety, robustness, or reasoning, let’s connect! 🚀
Since joining the Trustworthy AI Lab, I have been working on problems such as jailbreak vulnerabilities, adversarial in-context learning, safety alignment, and LLM unlearning. My work explores both the weaknesses of frontier language and reasoning models and practical ways to improve their reliability under real-world conditions.
More recently, I have been studying how reasoning traces and conversational context can steer model behavior, as well as how to align models more effectively without hurting their general usefulness. I am also interested in targeted unlearning: removing unwanted or sensitive information from models while keeping useful knowledge intact. At a broader level, I care about building AI systems that are not only capable, but also dependable and responsible. My long-term goal is to help bridge cutting-edge language model research with safer deployment in high-impact settings.
If you’re interested in trustworthy AI, language model safety, robustness, or reasoning, let’s connect! 🚀